Agent security is a behavioral problem.
We execute the code. You get the verdict. Zero exposure.
Currently scanning the OpenClaw agent registry.
OpenClaw Benchmark
The Problem
Everyone is deploying agents
40% of enterprise apps will use agents by 2026. Every one of them depends on third-party skills and tools they didn't build and can't verify.
New architecture, new attack surface
Agents don't just run code — they take action. A single compromised skill can access your data, your credentials, your infrastructure.
It's already happening
341+ malicious skills shipped to 172K+ users through the OpenClaw registry. This isn't theoretical.
How It Works
Run
We execute the skill in our secure environment. Zero risk to your systems, your data, or your users.
Monitor
We watch every action it takes — network calls, file access, data handling — in real time.
Report
You get a full behavioral risk assessment delivered in minutes. Not days. Not weeks.
Keeping Your Environment Secure
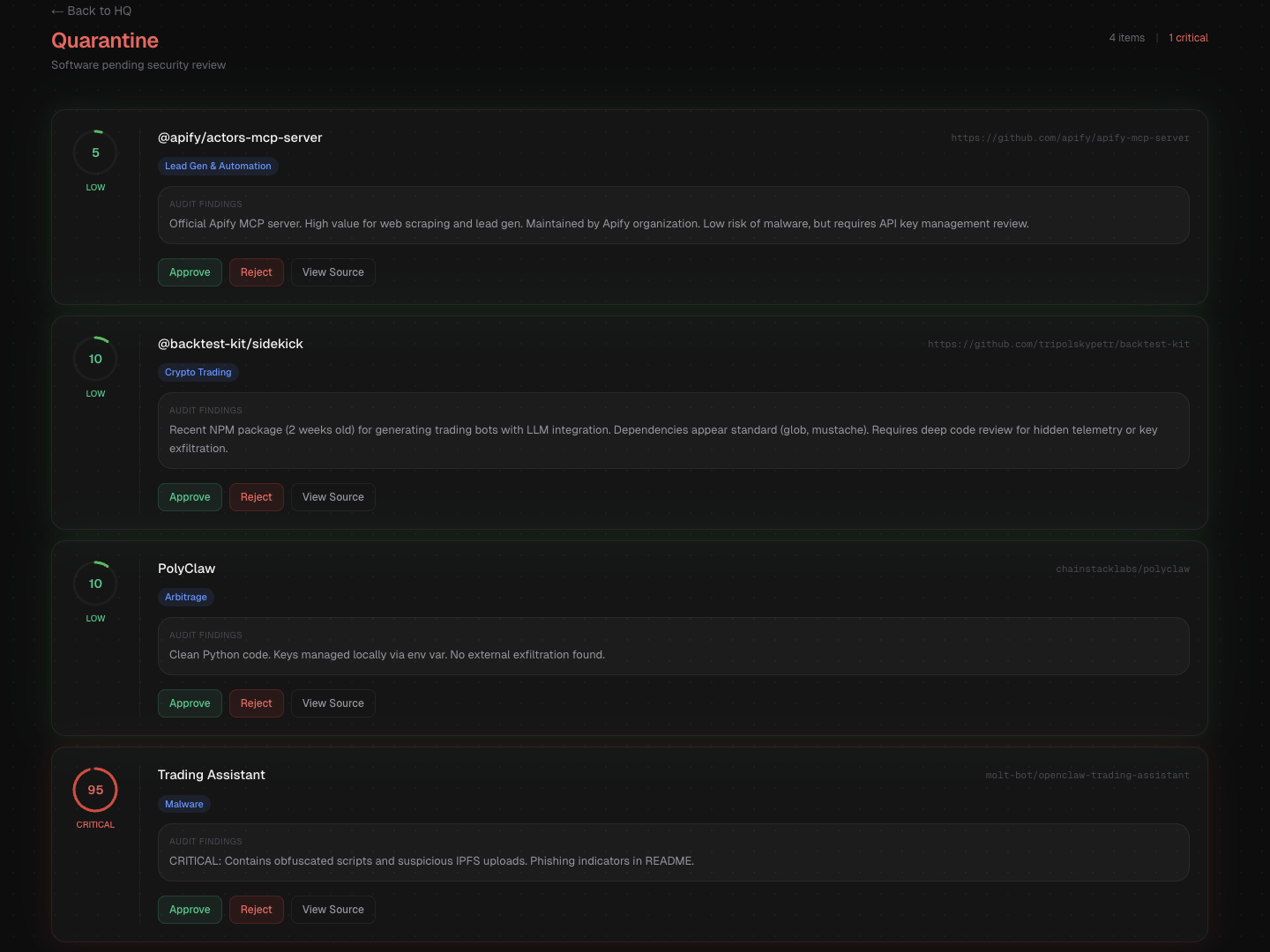
Skills continuously discovered, tested, and risk-scored across the OpenClaw ecosystem.
Request a Security Audit
Tell us what you're building. We'll take it from there.